

KI-Algorithmen: Alle 17, einfach erklärt
Algorithmen: Die Grundlage und Herausforderung der Künstlichen IntelligenzRechtliche Überlegungen bei der Anwendung von KI: Anforderungen an Transparenz<Die Illusion von Intelligenz: Algorithmen und ihre VielseitigkeitDer Small2Big Data-Ansatz: Kontinuierliche Datenerfassung für robuste KI-Algorithmen.
Algorithmus: Definition und Erläuterung
Ein Algorithmus ist eine exakte Anweisung zur Bewältigung eines spezifischen Problems, bei der das Ergebnis Y stets vorhersehbar ist, wenn die Eingabe X bekannt ist. Im Kontext der Künstlichen Intelligenz existieren jedoch keine festgelegten Lösungen. KI-Systeme erwerben stattdessen ihre Fähigkeiten durch die Auswertung von Trainingsdaten und erzielten Resultaten.
Algorithmen: Die Grundlage und Herausforderung der Künstlichen Intelligenz
Dennoch basiert auch KI letztlich auf Algorithmen – also auf Formeln, die in Programmiersprache geschrieben sind:
Die sogenannte Schwache KI setzt Algorithmen in der Automatisierung ein, um abgegrenzte Problemstellungen in eng definierten Bereichen zu lösen. Ebenso nutzt die Starke KI Algorithmen zur Analyse, Optimierung und Lösung von Problemen. Im Gegensatz zur Schwachen KI kann die Starke KI ihre Lösungsansätze auch auf andere Bereiche übertragen.

Oft wird die These aufgestellt, dass Algorithmen und Künstliche Intelligenz miteinander im Widerspruch stehen. (Foto: AdobeStock - 619226376 Adam)
Die glorreichen 17 KI-Algorithmen
-
Reinforcement Learning (Verstärkendes Lernen)
Algorithmen, die darauf abzielen, durch Interaktion mit einer Umgebung eine Strategie zu entwickeln, um Belohnungen zu maximieren, z. B. bei der Entwicklung von autonomen Agenten für Spiele oder Robotik.
-
Deep Learning
Eine Art von maschinellem Lernen, das neuronale Netzwerke mit vielen Schichten (Tiefen) verwendet, um komplexe Muster in großen Datenmengen zu lernen, verwendet in Bereichen wie Bilderkennung, Sprachverarbeitung und mehr.
-
Convolutional Neural Networks (CNNs)
Spezielle Art von neuronalen Netzwerken, die besonders gut für die Verarbeitung von Bildern und Videos geeignet sind.
-
Recurrent Neural Networks (RNNs)
Eine Art von neuronalen Netzwerken, die für die Verarbeitung von Sequenzen, wie z. B. Text oder Zeitreihen, geeignet sind.
-
Generative Adversarial Networks (GANs)
Ein Modell, das aus zwei neuronalen Netzwerken besteht - einem Generator und einem Diskriminator -, die gegeneinander trainiert werden, um realistische Daten zu generieren, oft für die Erzeugung von Bildern oder Musik.
-
Support Vector Machines (SVMs)
Eine Überwachungslernalgorithmus, der besonders gut für die Klassifizierung von Datenpunkten geeignet ist, indem er eine Trennlinie zwischen verschiedenen Klassen im Raum der Merkmale findet.
-
K-Means-Clustering
Ein unüberwachter Lernalgorithmus zur Gruppierung von Datenpunkten in K Cluster, wobei jeder Datenpunkt dem Cluster mit dem nächstgelegenen Mittelpunkt zugewiesen wird.
-
Decision Trees (Entscheidungsbäume)
Ein Modell, das Entscheidungsregeln in Form eines baumartigen Strukturs darstellt, die verwendet werden, um Daten zu klassifizieren oder zu prognostizieren.
-
Random Forests
Eine Ensemble-Technik, die aus einer Menge von Entscheidungsbäumen besteht und für Klassifikations- und Regressionsaufgaben verwendet wird.
-
Bayesian Networks
Grafische Modelle, die Wahrscheinlichkeitsverteilungen zwischen einer Menge von Variablen repräsentieren und für probabilistisches Schließen verwendet werden.
-
Neuroevolution
Eine Methode, bei der evolutionäre Algorithmen zur Optimierung von neuronalen Netzwerken verwendet werden, oft für die Entwicklung von Robotern oder anderen autonomen Agenten.
-
Fuzzy Logic
Eine Methode, die unscharfe Mengen verwendet, um Unsicherheiten zu modellieren und Entscheidungen in Systemen zu treffen, die nicht-binäre Eingaben erfordern.
-
Genetische Algorithmen
Eine Art von evolutionären Algorithmen, die Prinzipien der natürlichen Selektion und Vererbung anwenden, um optimale Lösungen für Optimierungsprobleme zu finden.
-
Natural Language Processing (NLP) Algorithmen
Algorithmen, die auf die Verarbeitung und das Verständnis von menschlicher Sprache abzielen, einschließlich Aufgaben wie Übersetzung, Zusammenfassung und Sentimentanalyse.
-
Markov Decision Processes (MDPs)
Ein mathematisches Modell für sequenzielle Entscheidungsprobleme, die in der Künstlichen Intelligenz und den Betriebswissenschaften verwendet werden.
-
Long Short-Term Memory (LSTM)
Eine spezielle Art von rekurrenten neuronalen Netzwerken, die für die Verarbeitung von Sequenzen mit langfristiger Abhängigkeit geeignet sind.
-
Ensemble Learning
Eine Technik, bei der mehrere Lernalgorithmen kombiniert werden, um eine bessere Vorhersagegenauigkeit zu erzielen, indem sie verschiedene Modelle miteinander kombinieren.
KI-Algorithmen einfach erklärt
#1 Künstliche Neuronale Netze (ANNs)
#2 Support-Vektor-Maschinen (SVMs)
#3 Entscheidungsbäume
#4 Zufällige Wälder / Random Forest
#5 K-Means-Clustering: im Fokus
Netzwerke mit langem Kurzzeitgedächtnis (LSTMs) sind eine revolutionäre Errungenschaft im Bereich des Deep Learnings. (Foto: AdobeStock - 652462916 MakZin)
#6 Gradient Boosting: Die Schlüsseltechnologie im Maschinellen Lernen
Als eine der Schlüsseltechnologien im Bereich des maschinellen Lernens hat Gradient Boosting signifikante Fortschritte ermöglicht. Dieser Algorithmus kombiniert geschickt mehrere schwache Modellergebnisse, um ein präzises Vorhersagemodell zu erstellen. Insbesondere in der Online-Werbung und bei der Erstellung von Ranglisten für die Websuche spielt Gradient Boosting eine entscheidende Rolle. Durch seine Fähigkeit, die Modellgenauigkeit kontinuierlich zu verbessern, trägt dieser Ansatz maßgeblich dazu bei, die Leistungsfähigkeit und Effektivität von Vorhersagemodellen zu steigern.
Der Hauptgedanke hinter Gradient Boosting besteht darin, in jeder Iteration ein neues Modell zu erstellen, das sich auf die Fehler des vorherigen Modells konzentriert. Dies geschieht, indem der Gradient des Verlustes (Fehlerfunktion) des vorherigen Modells berechnet wird und das neue Modell versucht, diesen Gradienten zu minimieren. Durch das Hinzufügen vieler solcher schwachen Modelle und die Kombination ihrer Vorhersagen kann Gradient Boosting sehr leistungsstarke Vorhersagen erzielen.
Ein bekanntes Beispiel für einen Gradient-Boosting-Algorithmus ist XGBoost (Extreme Gradient Boosting), der aufgrund seiner Effizienz und Genauigkeit in vielen Anwendungen weit verbreitet ist. Andere Implementierungen umfassen LightGBM und CatBoost.
Video: Das Problem mit den Algorithmen | MedienWissen2go | ZAPP | NDR
#7 Faltungsneuronale Netze (Convolutional Neural Networks, CNNs)
Faltungsneuronale Netze (Convolutional Neural Networks / CNNs) sind eine spezielle Art von künstlichem neuronalen Netzwerk, das häufig in der Bildverarbeitung und anderen Anwendungen verwendet wird, bei denen vor allem die räumliche Struktur der Eingabedaten wichtig ist.
CNNs verwenden spezielle Schichten, die als Faltungsschichten bezeichnet werden, um Merkmale in den Eingabedaten zu erkennen. Diese Schichten sind in der Lage, Merkmale wie Kanten, Formen und Texturen zu identifizieren, indem sie über das Eingangsbild gleiten und Filter auf die Daten anwenden. Diese Merkmale werden dann in den nachfolgenden Schichten kombiniert, um immer komplexere Muster und Informationen zu extrahieren.
CNNs haben sich als äußerst leistungsfähig für eine Vielzahl von Aufgaben erwiesen, darunter Bildklassifizierung, Objekterkennung, Gesichtserkennung, medizinische Bildgebung und mehr.
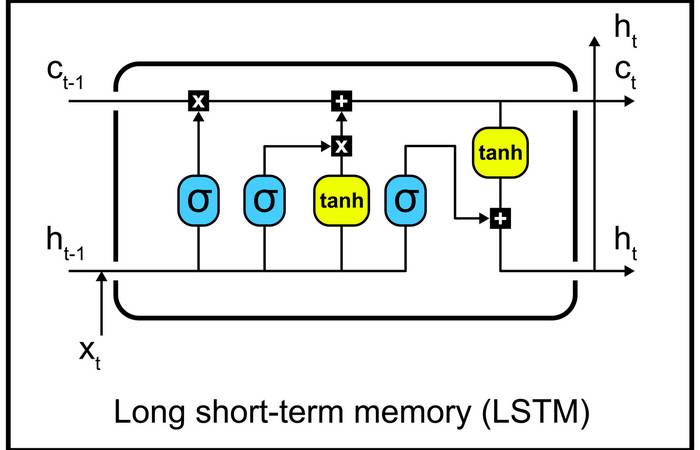
#8 Die Macht der LSTMs (Long Short-Term Memory): Eine Revolution im Bereich des Deep Learnings
Netzwerke mit langem Kurzzeitgedächtnis (LSTMs) sind eine revolutionäre Errungenschaft im Bereich des Deep Learnings. Diese Deep-Learning-Algorithmen wurden speziell entwickelt, um sequenzielle Daten wie Sprache und Text zu verarbeiten. Ihre Fähigkeit, komplexe langfristige Abhängigkeiten zu erfassen, macht sie zu einem unverzichtbaren Werkzeug für Anwendungen wie Handschrifterkennung, Spracherkennung und maschinelle Übersetzung. Mit ihrem einzigartigen Design haben LSTMs die Grenzen des Machbaren erweitert und einen Wendepunkt in der Entwicklung von KI-Systemen markiert.
Es handelt sich um eine spezielle Art von rekurrentem neuronalen Netzwerk (RNN), das entworfen wurde, um das Problem des Verschwindens des Gradienten bei der Rückwärtspropagation über lange Zeiträume zu lösen.
LSTM-Netzwerke sind besonders gut geeignet für die Verarbeitung und Vorhersage von Zeitreihendaten, wie beispielsweise Sprachverarbeitungsaufgaben (z. B. maschinelle Übersetzung, Textgenerierung) oder Zeitreihenanalysen (z. B. Aktienkursvorhersagen, Wettervorhersagen). Sie haben sich auch in anderen Anwendungen bewährt, bei denen es auf das Verständnis und die Verarbeitung von Sequenzen ankommt.
| KI-Algorithmus | Hauptanwendungsgebiet | Typische Beispielanwendung | Erfinder des Algorithmus |
|---|---|---|---|
| Support-Vektor-Maschinen | Klassifikation, Regression | Gesichtserkennung | Vladimir Vapnik |
| K-Means-Clustering | Clusteranalyse | Kunden-Segmentierung | James MacQueen |
| Neuronale Netze | Klassifikation, Regression | Bilderkennung | Frank Rosenblatt |
| Entscheidungsbäume | Klassifikation | Diagnose von Krankheiten | Ross Quinlan |
| Künstliche Neuronale Netze | Klassifikation, Regression | Spracherkennung | Warren McCulloch |
| Random Forest | Klassifikation, Regression | Vorhersage von Aktienkursen | Leo Breiman |
| Naive Bayes | Klassifikation | Spamfilter | Thomas Bayes |
| Genetische Algorithmen | Optimierung | Fahrzeugkonstruktion | John Holland |
| Rekurrente Neuronale Netze | Zeitreihenanalyse | Maschinelle Übersetzung | Seppo Linnainmaa |
| Principal Component Analysis (PCA) | Dimensionsreduktion | Gesichtserkennung, Datenkompression | Harold Hotelling |
| Lineare Regression | Regression | Vorhersage von Hauspreisen | Francis Galton |
| Quelle: Eigene Recherchen, eine Auswahl | |||
Rechtliche Überlegungen bei der Anwendung von KI: Anforderungen an Transparenz
Im weiteren Verlauf werden wesentliche rechtliche Aspekte und Überlegungen dargestellt, die Unternehmen bei der Implementierung von KI-Technologie in ihre Geschäftstätigkeiten beachten müssen.
Datenschutzanforderungen im Kontext von KI-Technologien
Unternehmen, die KI-Technologien in ihren Geschäftsbetrieb integrieren möchten, müssen sicherstellen, dass sie strenge Datenschutzanforderungen erfüllen. Es ist von größter Bedeutung, dass der Schutz personenbezogener Daten stets gewährleistet ist.
Dazu gehört das vollständige Verständnis und die Erfüllung aller Verpflichtungen im Zusammenhang mit der Erhebung, Verarbeitung und Speicherung solcher Daten. Durch die Implementierung effektiver Schutzmaßnahmen können die Datenschutzrechte von Einzelpersonen geschützt und die Einhaltung gesetzlicher Vorschriften wie der Allgemeinen Datenschutzverordnung (GDPR) in der Europäischen Union sichergestellt werden.
Datenschutzgerechte Datenerfassung und -verarbeitung
Die Integration von KI in Geschäftsprozesse erfordert die strikte Einhaltung der Grundsätze der Datenminimierung gemäß der Datenschutz-Grundverordnung (DSGVO). Dies bedeutet, dass nur die für rechtmäßige Zwecke unbedingt erforderlichen Daten erfasst und verarbeitet werden dürfen.
Durch die Vermeidung der Erfassung übermäßiger oder irrelevanter Informationen, die ein Risiko für die Privatsphäre darstellen könnten, können Organisationen potenzielle Datenschutzbedenken wirksam minimieren.
Transparente Information und Nutzerrechte im Zusammenhang mit KI
Die Sicherstellung von Transparenz bezüglich des Einsatzes von KI-Technologien ist von größter Wichtigkeit. Unternehmen sollten ihre Nutzer klar und deutlich darüber informieren, wie ihre persönlichen Daten verarbeitet werden, welche Zwecke die KI-Algorithmen verfolgen und welche Rechte die Nutzer haben, um ihre Daten einzusehen, zu korrigieren und zu löschen. Die Implementierung benutzerfreundlicher Zustimmungsmechanismen und die Befähigung von Einzelpersonen, ihre Datenschutzrechte auszuüben, sind entscheidende Schritte zur Gewährleistung der Einhaltung rechtlicher Vorschriften.
- das Erkennen von Mustern in Datenmengen,
- die Analyse von Zusammenhängen und
- die eigenständige Anwendung dieser Erkenntnisse zur Lösung von Aufgaben
Sorgfältige Risikobewertung und Datenschutzfolgenabschätzung (DPIA) für KI-Implementierungen
Angesichts der potenziellen Datenschutzrisiken, die mit der Einführung von KI-Technologien einhergehen, ist die Durchführung von gründlichen Risikobewertungen und Datenschutzfolgenabschätzungen (DPIA) von entscheidender Bedeutung. Diese Maßnahmen ermöglichen es Unternehmen, potenzielle Risiken zu identifizieren, die Auswirkungen auf die Privatsphäre zu bewerten und geeignete Schutzmaßnahmen zu ergreifen. Durch einen proaktiven Ansatz bei der Bewältigung von Datenschutzrisiken können rechtliche Probleme vermieden und das Vertrauen der Verbraucher gestärkt werden.
Verantwortlichkeit und Protokollierung im Rahmen der DSGVO
Um die Anforderungen der Datenschutz-Grundverordnung (DSGVO) zu erfüllen, sollten Organisationen einen Rahmen für die Verantwortlichkeit schaffen. Dies beinhaltet eine umfassende Dokumentation der KI-Systeme, der Datenverarbeitungsaktivitäten und der Einhaltung der Datenschutzgrundsätze. Durch das Führen detaillierter Aufzeichnungen und die Umsetzung interner Richtlinien und Verfahren können Organisationen ihre Verpflichtung zur Einhaltung von Gesetzen und Datenschutzstandards nachweisen.
Rechtsgrundlagen für die Datenverarbeitung im Zusammenhang mit KI
Für Unternehmen, die KI in ihre Geschäftsprozesse integrieren, ist die Prüfung der rechtmäßigen Grundlage für die Verarbeitung personenbezogener Daten von zentraler Bedeutung. Gemäß der Datenschutz-Grundverordnung (DSGVO) müssen Unternehmen sicherstellen, dass die Verarbeitung auf einer der gesetzlich vorgesehenen Rechtsgrundlagen basiert. Dazu gehören beispielsweise die Einholung einer Einwilligung, die Erfüllung vertraglicher Verpflichtungen, die Einhaltung gesetzlicher Vorschriften und die Wahrung berechtigter Interessen. Durch die Einhaltung der entsprechenden Rechtsgrundlage können Unternehmen den rechtlichen Anforderungen gerecht werden und gleichzeitig die Datenschutzrechte der Einzelpersonen respektieren.
Automatisierte Entscheidungsfindung und Profiling unter der DSGVO
Die Datenschutz-Grundverordnung (DSGVO) legt spezielle Anforderungen an die automatisierte Entscheidungsfindung und das Profiling fest. Organisationen sind verpflichtet, den betroffenen Personen aussagekräftige Informationen über die Logik, Bedeutung und Folgen solcher Verarbeitungen zur Verfügung zu stellen. Die Umsetzung angemessener Schutzmaßnahmen sowie die Bereitstellung eines Widerspruchsrechts gegen automatisierte Entscheidungen sind entscheidend für die Einhaltung der gesetzlichen Bestimmungen und die Gewährleistung von Transparenz.
Internationale Datenübertragungen und Compliance
Wenn KI-Systeme personenbezogene Daten außerhalb des Europäischen Wirtschaftsraums (EWR) übertragen, müssen Organisationen sicherstellen, dass angemessene Sicherheitsmaßnahmen getroffen werden. Dazu gehören die Nutzung von Standardvertragsklauseln, die Erlangung von Angemessenheitsbeschlüssen oder die Anwendung verbindlicher Unternehmensregeln, um sicherzustellen, dass Datenübertragungen den Anforderungen der Datenschutz-Grundverordnung (DSGVO) entsprechen. Durch die Umsetzung dieser Maßnahmen können Organisationen die Datenschutzanforderungen bei internationalen Datenübermittlungen erfüllen.
Entschlüsselung der KI: Drei zugängliche Algorithmen im Fokus
Für viele Menschen erscheinen die Algorithmen der Künstlichen Intelligenz wie undurchsichtige Blackboxes. Einige dieser Verfahren sind sogar für Experten schwer zugänglich. Gleichzeitig sind die Abläufe vieler leistungsstarker Algorithmen relativ einfach zu verstehen, ohne dass man ein Experte für KI sein muss. In diesem Blogbeitrag möchten wir uns drei solcher Verfahren genauer ansehen. Unser Ziel ist es, potenziellen Anwendern von KI zu helfen, diese Verfahren besser zu verstehen und somit den Einstieg in ihre eigenen Anwendungsfälle zu erleichtern.
-
Entscheidungsbäume: Selbstlernende Algorithmen zur Beurteilung der Fitness
Entscheidungsbäume stellen eine grundlegende Form von Algorithmen dar, die Entscheidungsmöglichkeiten ähnlich den Verzweigungen einer Baumkrone darstellen. Ein typischer Entscheidungsbaum-Algorithmus könnte zum Beispiel bestimmen, ob eine Person körperlich fit ist oder nicht.
Dies geschieht durch das Stellen einer Reihe von Fragen, möglicherweise durch einen Chatbot, der den Benutzer interviewt. Jede Antwort beeinflusst, welche Frage als nächstes gestellt wird.
Zum Beispiel könnte eine Person im Alter von 35 gefragt werden, ob sie regelmäßig Sport treibt, während eine Person im Alter von 17 gefragt wird, wie oft sie Pizza isst.
Am Ende jedes Pfades wird die Person entweder der Klasse "fit" oder "nicht fit" zugeordnet.

Entscheidungsbäume stellen eine grundlegende Form von Algorithmen dar, die Entscheidungsmöglichkeiten ähnlich den Verzweigungen einer Baumkrone darstellen. (Foto: AdobeStock - 278365163 tomertu)
Was Entscheidungsbäume besonders macht, ist ihre Fähigkeit, von selbst zu lernen, welche Fragen gestellt werden sollen und wie diese Fragen basierend auf den Antworten angeordnet werden sollen. Dies geschieht automatisch, ohne dass eine externe Einflussnahme erforderlich ist.
Der Algorithmus lernt durch interne Optimierungskriterien, wie beispielsweise die Qualität der Trennung zwischen den Zielklassen "fit" und "nicht fit". Faktoren wie Alter, Ernährungsgewohnheiten und körperliche Aktivität werden dabei angemessen berücksichtigt.
-
Vorhersage des universitären Notendurchschnitts mittels linearer Regression
Dieses Konzept dürfte vielen bekannt sein. Nehmen wir an, Sie möchten mithilfe der schulischen Notendurchschnitte zukünftiger Studenten deren universitären Notendurchschnitt vorhersagen.
Die schwarzen Punkte repräsentieren vergangene Daten: die schulischen Notendurchschnitte von Studenten, deren universitäre Noten bereits bekannt sind.
Ein Algorithmus berechnet nun eine optimale Anpassungslinie (hier in Rot dargestellt; optimal bedeutet hier, dass die Abweichungen insgesamt möglichst gering sind). Diese Anpassungslinie spiegelt das bisherige Verhältnis zwischen Schulnoten und Hochschulnoten wider und kann auf neue Studentengenerationen angewendet werden.

Dieses Konzept dürfte vielen bekannt sein. (Foto: AdobeStock - 100834685 Dmitry Grushin)
Auf diese Weise kann unser Algorithmus eine Prognose über den universitären Notendurchschnitt abgeben.
-
k-Nearest-Neighbor-Algorithmus (kNN): Datenklassifizierung durch Nachbaranalyse
Dieser Algorithmus ermöglicht es, ähnliche Datenpunkte („Nachbarn“) zu einem bestimmten Datenpunkt zu identifizieren und ihn dann derjenigen Klasse zuzuordnen, die bei den Nachbarn am häufigsten vertreten ist.
Um das Konzept besser zu verstehen, können wir es an einem Beispiel veranschaulichen: Angenommen, Sie sind Dermatologe und haben in der Vergangenheit viele Hautläsionen als gut- oder bösartig klassifiziert. Sie vermuten, dass die Länge und Breite der Läsionen eine entscheidende Rolle spielen. Basierend auf vergangenen Diagnosen wissen Sie, welche Kombinationen von Länge und Breite zu welchem Ergebnis geführt haben.
Um zukünftige Diagnosen zu unterstützen, setzen Sie den kNN ein. Sie stellen die Breite auf der x-Achse und die Länge auf der y-Achse dar. Blaue Punkte entsprechen gutartigen Läsionen, rote bösartigen. Der gelbe Punkt stellt eine noch nicht klassifizierte Läsion dar. Der kNN hilft Ihnen dabei, eine Diagnose zu treffen.
Übrigens steht das "k" im kNN für die Anzahl der betrachteten Nachbarn. Die Auswahl von k kann zu unterschiedlichen Ergebnissen führen.
Wenn Sie k=3 wählen, wird das neue Muttermal (der gelbe Punkt) als gutartig klassifiziert, da zwei der drei nächsten Nachbarn blau sind und nur einer rot ist. Bei k=5 überwiegen jedoch die roten Nachbarn (drei von fünf), wodurch das neue Muttermal als bösartig klassifiziert wird.
Die Bestimmung des optimalen k ist eine nicht-triviale Aufgabe und hängt stark vom Anwendungsfall ab. Ebenso muss die Definition von "Abstand" oder "Nachbarschaft" berücksichtigt werden. Für zweidimensionale Räume wie im Beispiel ist dies einfach, aber auch für höherdimensionale Räume stehen Standardmaße zur Verfügung.
Weitere Anwendungen dieser Verfahren umfassen:
- Automatische Klassifizierung eingehender Dokumente wie Rechnungen, Mahnungen oder Terminanfragen.
- Selbstständige Extraktion von Informationen wie Namen, Adressen und Datumsangaben.
- Vorhersage laufender oder zukünftiger Prozesse, beispielsweise in Fertigungsabläufen.
Dieser Algorithmus ermöglicht es, ähnliche Datenpunkte („Nachbarn“) zu einem bestimmten Datenpunkt zu identifizieren und ihn dann derjenigen Klasse zuzuordnen, die bei den Nachbarn am häufigsten vertreten ist. (Foto: AdobeStock - 358888374 Sidartha)
Sobald das Grundprinzip verstanden ist, fällt der Schritt zur Weiterentwicklung der Verfahren nicht mehr so schwer. Auch bei komplexeren Algorithmen ist es nicht unbedingt erforderlich, die genaue Funktionsweise zu verstehen, sondern vielmehr zu wissen, welche Verfahren sich für bestimmte Problemstellungen eignen und wie man ihre Leistungsfähigkeit optimieren kann.
Wenn Sie tiefer in das Thema eintauchen möchten, laden wir Sie herzlich ein, unsere kostenlosen Seminare im November zu besuchen oder sich direkt an mich zu wenden. Ich stehe Ihnen gerne für Fragen und zur Diskussion Ihrer KI-Anwendungsideen zur Verfügung!
Der Small2Big Data-Ansatz: Kontinuierliche Datenerfassung für robuste KI-Algorithmen.
Die Herausforderung besteht darin, gelabelte Daten aus dem Anwendungskontext zu beschaffen, um KI-Algorithmen und KI-basierte Modelle zu entwickeln. Besonders für robuste KI-Algorithmen sind große Datenmengen erforderlich, die vor ihrer Nutzung gesammelt werden müssen. Ziel ist es, KI-Funktionen auch für bisher unerforschte Themenbereiche zu erforschen und Daten zu erheben, um die Qualität der KI-Funktionen in Zukunft zu optimieren.
Im Small2Big Data-Ansatz werden die Daten in Echtzeit erhoben, wobei eine kontinuierliche Datenerfassung im Anwendungskontext als Grundlage für die KI-Algorithmen dient. Das Hauptziel besteht darin, gelabelte Daten im Rahmen des Small2Big Data-Ansatzes zu erheben, um die Entwicklung von KI-Applikationen zu unterstützen. Hierbei wird eine kontinuierliche Datenqualitätssicherung, Datenaufbereitung und Datenlabeling durchgeführt, um die Daten für die Nutzung durch andere Partner vorzubereiten.
Transparenz in der Praxis: Die Nachverfolgbarkeit von KI-Algorithmen
In einer Vielzahl von Branchen und Anwendungen überholen KI-Verfahren, insbesondere maschinelle Lernverfahren, zunehmend menschliche Entscheidungsträger. Sie kategorisieren Luftbilder, summarisieren Nachrichtentexte oder prognostizieren den Gasverbrauch - häufig mit einer Genauigkeit und Geschwindigkeit, die weit über menschliche Möglichkeiten hinausgehen.
Die Herausforderung intransparenter Entscheidungen
Trotz der weitreichenden Einsatzmöglichkeiten von KI-Technologien gibt es auch deutliche Schattenseiten. Ein gemeinsames Merkmal vieler Lernverfahren ist ihre mangelnde Nachvollziehbarkeit, Erklärbarkeit und Transparenz bei der Entscheidungsfindung, die durch hochkomplexe Modelle getroffen werden.
Besonders in Situationen, in denen Menschen direkt betroffen sind - wie bei der Hautkrebserkennung im Gesundheitswesen oder der Personalauswahl in öffentlichen Einrichtungen - wird neben der Genauigkeit des Modells auch die Nachvollziehbarkeit des Ergebnisses entscheidend. In solchen Fällen kann eine Expertenvalidierung der Entscheidung im Zweifelsfall, beispielsweise aufgrund rechtlicher Verpflichtungen, unerlässlich sein.
Vom Forschungslabor zur Unternehmensrealität: Explainable AI im Wandel
Das Fachgebiet "Explainable AI" (XAI) des maschinellen Lernens konzentriert sich auf Methoden und Techniken, die Einblicke in die Black Box der KI-Algorithmen ermöglichen sollen. Derzeit befindet es sich in einer faszinierenden Phase des Übergangs vom reinen Forschungsbereich hin zur praktischen Umsetzung in Unternehmen. Neben komplexen mathematischen Verfahren und deren Implementierung werden zunehmend auch einfach zugängliche Demonstratoren entwickelt, die das Thema auch Nicht-Spezialisten näherbringen sollen.

Das Fachgebiet "Explainable AI" (XAI) des maschinellen Lernens konzentriert sich auf Methoden und Techniken, die Einblicke in die Black Box der KI-Algorithmen ermöglichen sollen. (Foto: AdobeStock - 588458024 Eduardo Lópe)
Fazit
Zusammenfassend lässt sich sagen, dass die rechtlichen Aspekte und potenziellen Risiken im Zusammenhang mit KI-Algorithmen eine wichtige Rolle spielen. Es ist entscheidend, sich der rechtlichen Rahmenbedingungen bewusst zu sein, die den Einsatz und die Entwicklung von KI-Technologien regeln. Dies umfasst Fragen zum Datenschutz, zur Haftung und zur ethischen Verantwortung bei der Verwendung von KI. Darüber hinaus müssen die potenziellen Risiken, wie etwa Bias und Diskriminierung, sorgfältig berücksichtigt werden, um negative Auswirkungen auf Gesellschaft und Individuen zu minimieren. Ein verantwortungsvoller Umgang mit KI erfordert daher eine gründliche Analyse der rechtlichen und ethischen Dimensionen sowie geeignete Maßnahmen zur Risikominderung und zur Förderung einer verantwortungsbewussten KI-Entwicklung und -Nutzung.










